RESEARCH PROJECT
DocWise – Turning Documents Into Insights with Vision AI
Using a powerful Vision Model to convert documents, handwriting, tables, and forms into accurate, structured data.
Try it out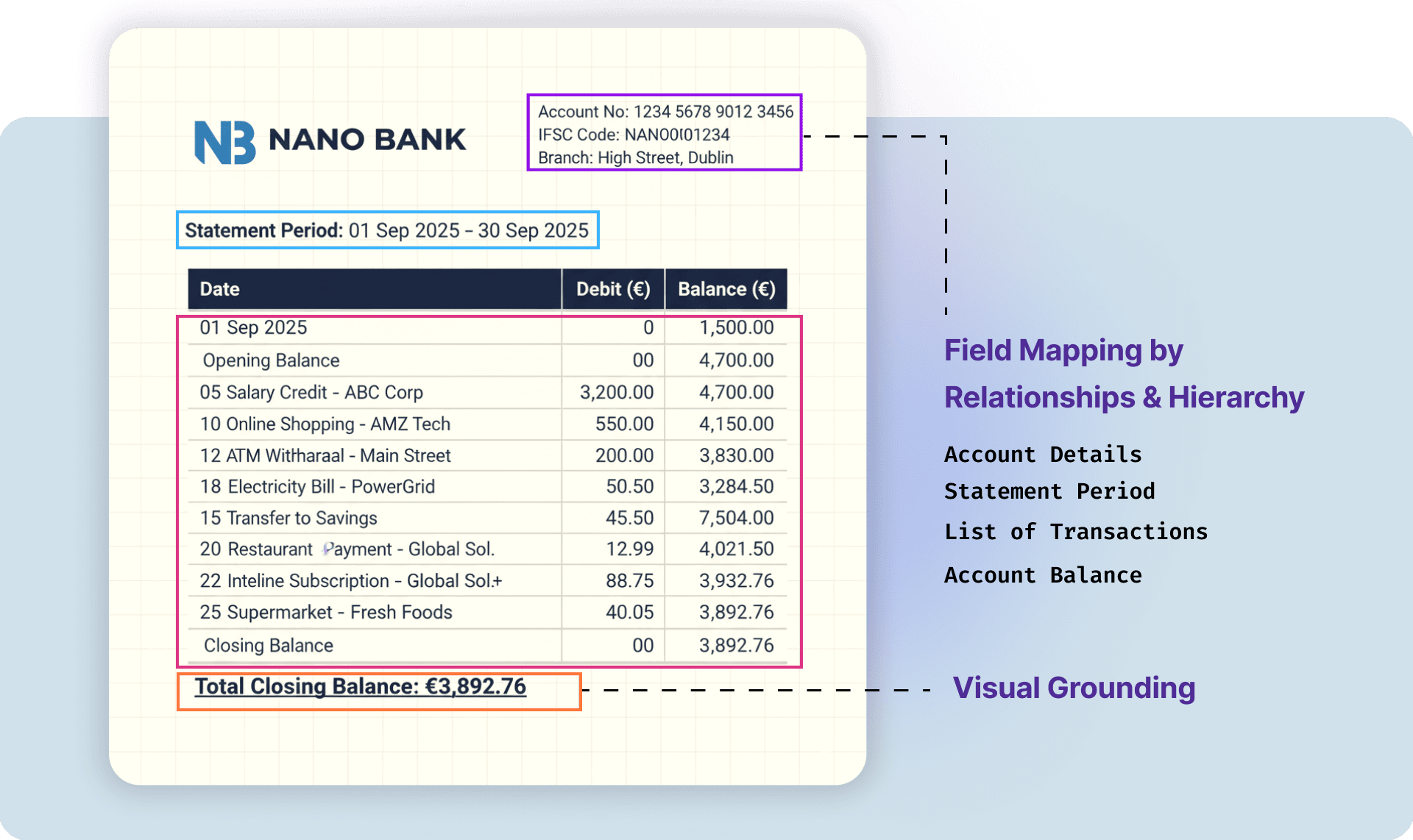

Key capabilities
Understand any document—text,
layout, and meaning
Docwise interprets documents with human-like AI—reading, structuring, and extracting data. From certificates to invoices and IDs, insights are just a click away.
Handles Complex & Unstructured Layouts
Understands diverse document formats, even those with irregular layouts or noisy backgrounds.

Smart Table & Form Extraction
Extracts structured data from tables, forms, and grids with precision—no manual work needed.

Handwriting Recognition with Context
Reads and interprets handwritten text accurately, even when mixed with printed content.
Visual Grounding for Deeper Context Awareness
Docwise uses visual grounding to connect textual information with its visual context — linking what’s written to where it appears. This helps the system accurately interpret document layouts, identify key-value pairs, and associate tables, signatures, or stamps with their related content.
State-of-the-art document reasoning
DocWise goes beyond OCR and sets a new benchmark by reasoning over complex document structures.
Highlights:
- Excels at reasoning over content to infer context and relationships between sections.
- Accurately reads and interprets text from low-resolution or blurred document images.
Our Approach
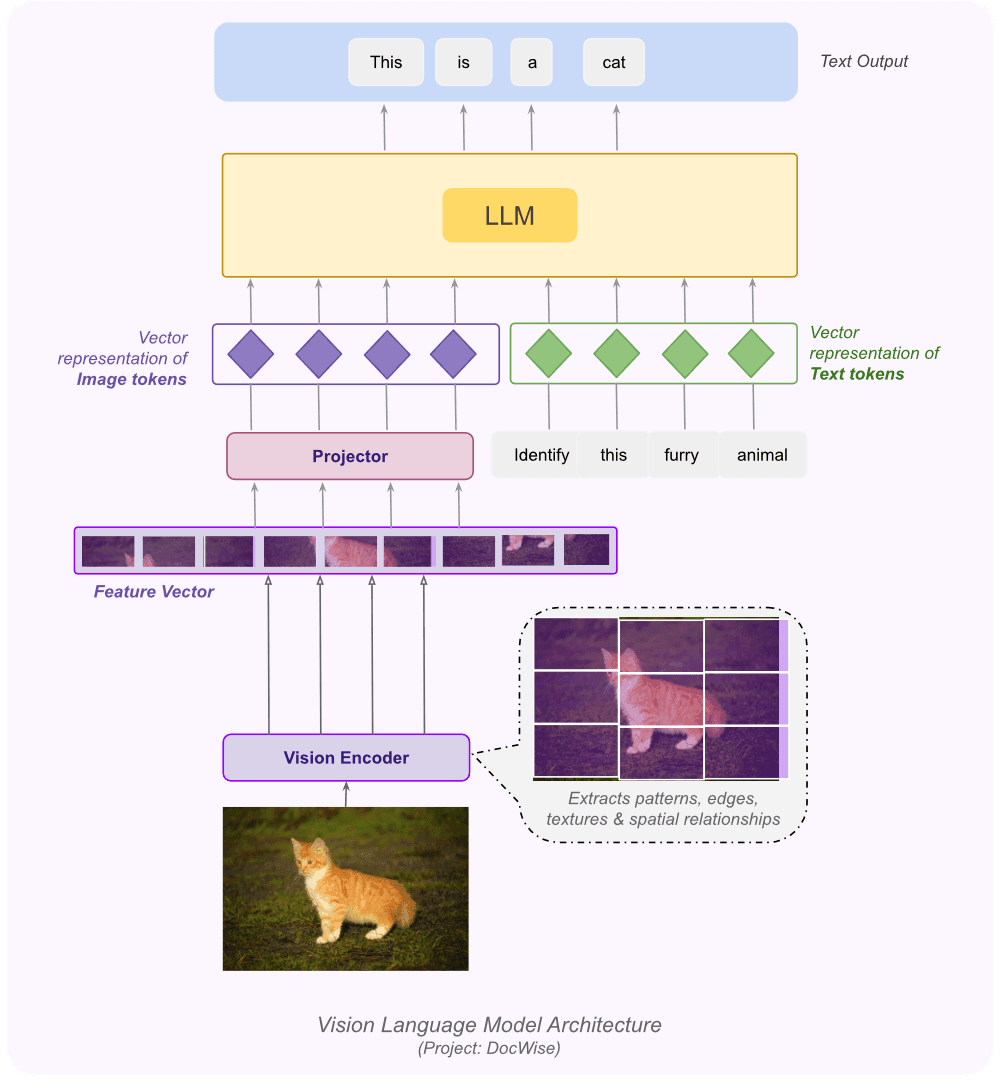
Vision-Language Model at the Core
Seamlessly combining visual context and textual understanding to interpret and reason over complex documents.
A leap beyond OCR
Our use of VLMs enables context-aware document reasoning, surpassing OCR by recognizing relationships, intent, and even the structure of poorly scanned or handwritten documents.
Key Highlights:
- VLMs go beyond extracting text — they interpret layout, semantics, and relationships between elements.
- It can read and reason even in poor lighting, blurs, or handwritten inputs.
- VLM enables Q&A over documents, summarization, and intent-based responses.
- Instead of flat text, VLM can preserve tables, forms, and hierarchies, crucial for downstream processing.
- By fusing vision and language, VLM mimics how humans read documents — interpreting rather than transcribing.
System Architecture
DocWise Processing Flow
Docwise is a comprehensive document processing pipeline built around a Vision-Language Model (VLM) core. It is designed to go beyond text extraction, achieving a deeper multimodal understanding of documents — combining layout, visual cues, semantics, and contextual reasoning. The architecture is modular, scalable, and adaptable for both research and enterprise applications.

Multi-format Document Parsing
Docwise supports parsing of documents in multiple formats including PDF, scanned images, DOCX, PPT, and HTML. Its parsing engine ensures format-agnostic ingestion, normalizing diverse sources into a unified representation. Each page is pre-processed for layout integrity, ensuring accurate handling of vector-based and rasterized inputs.
Vision-Language Model (VLM)
The VLM acts as the intelligence hub of Docwise. Instead of relying on OCR, the model jointly understands visual and textual signals, enabling it to reason about document content holistically.
Advanced Page Layout & Structure Analysis
At this stage, Docwise performs fine-grained layout interpretation. The model detects and organizes complex structures such as multi-column text, headers, footers, tables, code snippets, mathematical formulas, images, and captions. It also infers reading order and visual hierarchy.
Visual Grounding and Metadata Understanding
Docwise incorporates a visual grounding engine that links textual and graphical components to their physical coordinates on a page. Beyond text, it extracts metadata, image embeddings, and layout context.
Structured Data Extraction
Once the document’s semantic and spatial structure is established, Docwise performs field-level data extraction guided by predefined JSON schemas.
RAG and Contextual Chunking
We support hybrid and hierarchical chunking for RAG-based applications, ensuring each content segment retains semantic and spatial coherence for improved retrieval quality and precise grounding during LLM queries.
Potential applications
Our Vision AI opens up new possibilities for automating document workflows across industries. Here are some key use cases:

Agentic Document Processing
Enable AI agents to autonomously handle document tasks like classification, summarization, and routing—ideal for workflows in insurance, banking, and compliance-heavy industries.
Smart Document QnA & Search
Empower users to ask questions and get instant, context-aware answers from long or complex documents—perfect for legal reviews, contracts, and policy documents.

Intelligent Form Filling
Automate the extraction and entry of data from invoices, prescriptions, or claim forms—even with noisy, handwritten, or poorly scanned inputs—saving time and minimizing errors.
Try it out
Experience the power of DocWise Vision AI for yourself. Upload a document and see how it interprets, extracts, and reasons over complex layouts and content.

January 16, 2026
Document AI in 2026: A Comparison of Open VLM-Based OCR
A practical benchmark on real-world documents: evaluating layout, tables, handwriting, and noisy scans

November 8, 2025
Meet Docling — The Open-Source Document AI Pipeline
Hands-On with IBM’s Docling: Parsing, Structuring, and Enabling AI-Driven Document Processing
Collaborate. Share. Grow.
Join our Discord community, where you can exchange ideas, collaborate on projects, and grow alongside people passionate about advancing AI.
 Join Our Discord Community
Join Our Discord Community© All rights reserved | Kriyam.ai 2026



